 |
VOOZH | about |
|
VOOZH | about |
Exploratory Data Analysis (EDA) is the foundation of every data science project. It is the process of examining datasets to understand their structure, identify patterns, detect anomalies and extract meaningful insights. Before applying any machine learning or statistical models, data must be cleaned, transformed and explored this is where EDA plays an important role.
EDA helps answer important questions such as:
For example, in a student performance dataset, some records may have missing scores or inconsistent subject names (such as “Math” and “Mathematics”). EDA helps identify and fix such issues, ensuring the dataset is ready for analysis and modeling.
The most commonly used Python libraries for EDA are NumPy, Pandas, Matplotlib and Seaborn. Each library serves a specific purpose in the EDA workflow.
NumPy is the core library for numerical computing in Python. It is designed to handle large, multi-dimensional arrays efficiently and provides fast mathematical and statistical operations.
Mean: 77.77777777777777, Median: 65.0, Standard Deviation: 44.541560561838764
This example shows how NumPy quickly computes descriptive statistics and highlights the impact of outliers (the value 200) on the mean.
Pandas is built on top of NumPy and is designed for working with structured, tabular data. It introduces two main data structures:
Pandas makes data cleaning, transformation and analysis simple and intuitive.
Name Marks 0 A 78.0 1 B 85.0 2 C NaN 3 D 90.0 Name Marks 0 False False 1 False False 2 False True 3 False False 84.33333333333333
This example demonstrates how Pandas identifies missing values and computes summary statistics.
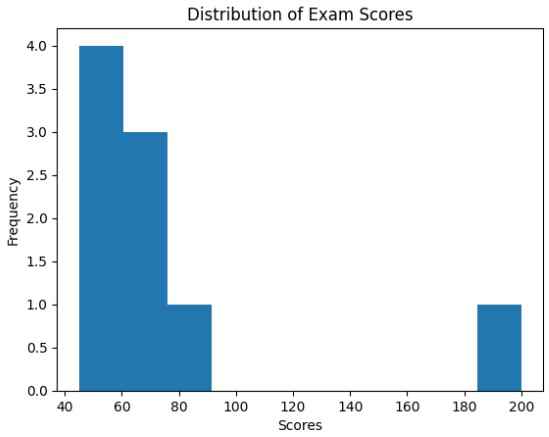
Matplotlib is a powerful and flexible plotting library used to visualize data in various formats. It helps convert numerical data into meaningful visual representations.
Output:
This histogram helps visually identify the presence of outliers in the dataset.
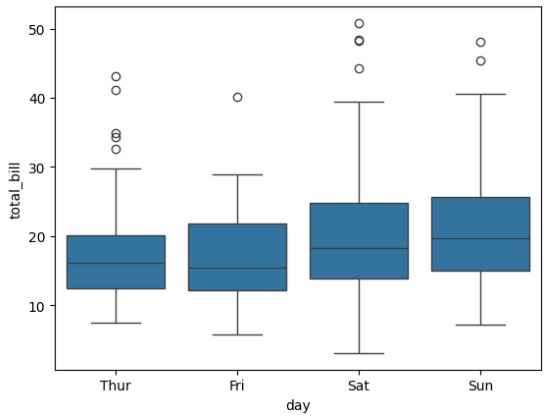
Seaborn is built on top of Matplotlib and focuses on statistical visualizations. It provides a high-level interface for creating attractive and informative plots with minimal code.
Output:
This boxplot helps analyze data distribution and detect outliers across different categories.
Let's implement complete workflow for performing EDA: starting with numerical analysis using NumPy and Pandas, followed by insightful visualizations using Seaborn to make data-driven decisions effectively.
To strengthen your understanding, explore these real-world projects:
Web scraping is the automated process of extracting data from websites for analysis. It is useful when datasets are not readily available.
{kind=link}
{kind=link}
{kind=link}
{kind=link}